Лабораторная работа № 7
Статистические данные могут быть представлены как количественными (числовыми непрерывными или дискретными), так и качественными (категориальными порядковыми или номинальными) переменными.
Обычно используют следующие типы шкал измерений: номинальная (названий или категорий), порядковая (ординальная), интервальная и относительная (шкала отношения или абсолютная шкала). Соответственно имеются четыре типа переменных: номинальная, порядковая (ординальная), интервальная, относительная (абсолютная).
1) Номинальные переменные используются только для качественной классификации. Это означает, что данные переменные могут быть измерены только в терминах принадлежности к некоторым существенно различным классам, при этом вы не сможете определить количество или упорядочить эти классы. Часто номинальные переменные называются категориальными. Примером номинальных переменных являются фирма-производитель, тип товара, признак (болен - здоров) и т. д.
2) Порядковые переменные позволяют ранжировать (упорядочить) объекты, если указано, какие из них в большей или меньшей степени обладают качеством, выраженным данной переменной. Однако, они не позволяют определить «на сколько больше» или «на сколько меньше» данного качества содержится в переменной. Порядковые переменные иногда также называют ординальными.
Категориальные и порядковые переменные особенно часто возникают при анкетировании, т.к. естественно отражают характер мышления человека.
Первым этапом статистического анализа данных является частотный анализ. Для проведения частотного анализа категориальных данных используют построение и изучение частотных таблиц. Частотная таблица (ниже) построена по результатам опроса студентов об их психическом состоянии и социальном положении.

Каждая строка частотной таблицы описывает одно возможное значение:
· Строка с пометкой нет данных представляет наблюдения, в которых не было дано никакого ответа.
· Всего имеется 107 допустимых ответов, а также одно наблюдение, в котором психическое состояние неизвестно (данные отсутствуют либо утеряны).
· Первый столбец содержит метки отдельных значений (крайне неустойчивое, неустойчивое, устойчивое).
· Во втором столбце под заголовком "Frequency (Частота)" приведена частота каждого из вариантов ответа на вопрос из теста. Так, например, 20 человек на вопрос о психическом состоянии дали ответ: "крайне неустойчивое", а 40 человек — "неустойчивое".
· В третьем столбце показана процентная частота каждого ответа. Процентная частота соответствует отношению каждого из вариантов ответа к общему количеству опрашиваемых, включая утерянные значения.
· В четвертом столбце дано допустимое процентное значение. При определении этого значения утерянные данные исключаются.
· Последний столбец содержит накопленные процентные значения. Накопленные проценты — это сумма процентных частот допустимых ответов. Так, например, процент респондентов, которые дали ответ крайне неустойчивое или неустойчивое, составляет 56,1%. Это число определяется выражением: 18,7% + 37,4% = 56,1%.
· В последней строке содержится сумма всех столбцов (Всего).
Еще пример частотной таблицы

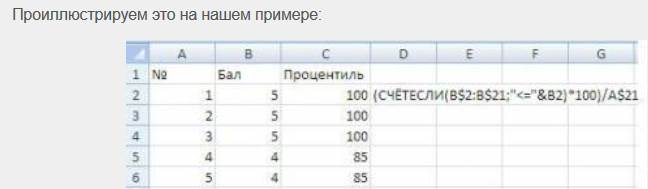
Для данных, имеющих форму частотной таблицы, определение медианы и остальных процентилей обычным методом будет слишком неточным. В таких случаях есть возможность вычислить медиану и любые другие процентили более точным методом. Мы поясним это на примере стоматологических данных.
Осуществим кодирование ответов вопроса

Подсчитаем медиану: середина ранжированного ряда = 2

При определении медианы обычным методом ее значение равно 2. Это значение, хотя формально и правильное, но дает совершенно неудовлетворительный, недостаточно значимый результат. В данном случае, когда данные являются концентрированными, для уточнения медианы применяется следующая расчетная формула:

Здесь:
n - Количество измеренных значений;
m - Класс, в котором находится медиана;
u - Нижняя граница класса m;
fm - Абсолютная частота в классе m;
Fm-1 - Накопленная частота вплоть до предыдущего класса m — 1;
B - Ширина класса.
Следовательно, решающее значение имеет правильный выбор границ классов; их следует выбирать так, чтобы значения кодовых чисел соответствовали середине каждого класса. В данном примере для границ классов следует выбрать значения
-0,5 0,5 1,5 2,5 3,5 4,5
Ширина класса равна 1.
Следовательно,
n = 2548;
m = 3 (так как медиана находится в третьем классе);
u = 1,5;
fm = 921;
Fm-1 = 109 + 389 = 498;
b = 1;

Если сравнить это значение со средним значением (2,24), то можно установить следующее правило — оказывается, что при распределении со сдвигом вправо (как в данном случае) медиана больше среднего значения.
По определению, медиана — это значение, выше и ниже (правее и левее) которого расположено по 50% всех значений, если они упорядочены по величине.
Обобщая эту характеристику, мы приходим к определению так называемых процентилей. Эти характеристики позволяют, например, указать значение, ниже которого лежит 10% всех значений (а выше расположено 90% значений). Чаше всего применяются процентили 25% и 75%, называемые также соответственно первым и третьим квартилями.
Формула вычисления процентиля для любого значения:

Здесь:
m - Класс, в котором находится процентиль;
u - Нижняя граница класса m;
P - Процентное значение процентиля;
hm - Процентная частота в классе m;
Hm-1 - Процентная накопленная частота в классе m-1
b - Ширина класса;
Для процентиля 50 % (Р = 50) после некоторых преобразований получается формула для медианы, приведенная выше.
Задание №1
1 Построить частотную таблицу для категориальных данных.
2 Подсчитать медиану
3 Подсчитать процентили: 10%, 25%, 50%, 75%
4 Сделать качественные выводы о распределении.


Для анализа связи результатов ответов на разные вопросы используют таблицы сопряженности. Они строятся объединением результатов ответов на вопросы. Т аблица сопряженности - средство представления совместного распределения двух переменных, предназначенное для исследования связи между ними. Таблица сопряженности является наиболее универсальным средством изучения статистических связей, так как в ней могут быть представлены переменные с любым уровнем измерения.
Строки таблицы сопряженности соответствуют значениям одной переменной, столбцы - значениям другой переменной (количественные шкалы предварительно должны быть сгруппированы в интервалы). На пересечении строки и столбца указывается частота совместного появления fij соответствующих значений двух признаков xi и yj. Сумма частот по строке fi называется маргинальной частотой строки; сумма частот по столбцу fj - маргинальной частотой столбца. Сумма маргинальных частот равна объему выборки n; их распределение представляет собой одномерное распределение переменной, образующей строки или столбцы таблицы.
В таблицах сопряженности могут быть представлены как абсолютные, так и относительные частоты (в долях или процентах). Относительные частоты могут рассчитываться по отношению:
- к маргинальной частоте по строке
- к маргинальной частоте по столбцу
- к объему выборки
Например:

Далее осуществляется более подробный анализ полученных в таблице данных.
16 респондентов оценивают свое психическое состояние как "крайне неустойчивое", а 5 респондентов-мужчин — как "очень устойчивое". Если для таблицы сопряженности приняты параметры по умолчанию, то в каждой ячейке отображается только абсолютная частота.
Числа в последней строке и в последнем столбце (Total) показывают суммы значений соответственно по строкам и столбцам. В данном примере суммы по строкам указывают, что 44 (16+18+9+1) опрошенных — лица женского пола, а 62 — мужского. Суммы по столбцам показывают, что 19 опрошенных (16 + 3) оценивают свое психическое состояние как "крайне неустойчивое", 40 как неустойчивое, 41 как устойчивое и 6 как "Очень устойчивое". При анализе принимались в расчет 106 допустимых наблюдений. Полученные результаты мы можем интерпретировать следующим образом:
· Из 106 опрошенных, которые учитывались при анализе, — 44 женщины и 62 мужчины.
· 16 женщин оценивают свою психику как "крайне неустойчивую", тогда как для мужчин это количество составляет только 3.
· Лишь одна женщина считает свое психическое состояние "очень устойчивым", а мужчин с таким состоянием пятеро.
Даже первое впечатление, которое возникает при анализе таблицы сопряженности, свидетельствует о том, что зависимость между переменными Пол и Психическое состояние существует. Женщины считают свое психическое состояние более неустойчивым, чем мужчины. Исследуем эту зависимость чуть более детально; для этого нам понадобится точно ответить на следующие вопросы:
· Существует ли зависимость вообще?
· Что можно сказать об интенсивности этой зависимости?
· Что можно сказать о направлении и характере этой зависимости?
Подсчитаем в таблице ожидаемые частоты. Они вычисляются как произведение сумм соответствующей строки и столбца, деленное на общую сумму частот. Например, ожидаемая частота для женщин с "крайне неустойчивым" психическим состоянием 7,9 = (16 + 18 + 9 + 1) x (16 + 3) / 106.

Эти данные мы можем интерпретировать так:
Для значений переменной Психическое состояние "крайне неустойчивое" и "неустойчивое" абсолютная частота у опрашиваемых женщин выше, чем ожидаемая (16 и 7,9; 18 и 16,6), тогда как при значениях "устойчивое" и "очень устойчивое" она ниже (9 и 17.0; 1 и 2,5).
У опрашиваемых мужчин мы находим противоположную тенденцию. Для значений "крайне неустойчивое" и "неустойчивое" абсолютная частота ниже, чем ожидаемая (3 и 11,1; 22 и 23,4), тогда как для значений "устойчивое" и "очень устойчивое" она выше 32 и 24,0; 5 и 3,5). Эти результаты мы можем объединить в следующую таблицу:

Таким образом, первоначальное впечатление, что женщины считают свое психическое состояние менее устойчивым, чем мужчины, подтверждается.
Задание №2
1 Построить таблицу сопряженности и выдвинуть предположения о связи ответов на вопросы
2 Подсчитать ожидаемые частоты и сделать качественные выводы о зависимости признаков
Задание №3
Можно подсчитать средние характеристики по какой-либо важной характеристике опроса и интерпретировать их.
Например.
Респонденты опроса о психическом состоянии и социальном положении имеют средний возраст 22,24 года. Медиана составляет 22. Большинству респондентов 21 год (это мода). Самому молодому респонденту 18 лет (минимум), самому старшему — 29 лет (максимум). Самый старший респондент на 11 лет старше самого молодого (размах). Стандартное отклонение составляет 2,19. Следовательно, дисперсия — квадрат стандартного отклонения — равна (2,19)2 = 4,79.