Переключатель Choose observations to maximize initial between-cluster distances. Если Вы выбираете этот переключатель, наблюдения или объекты будут установлены как начальные центры кластера. (1) программа выберет первые номера кластеров случаев, чтобы быть соответствующими центрами кластера; (2) последующие случаи заменят предыдущие центры кластера, если их самое маленькое расстояние к любому из центров кластера больше, чем самое маленькое расстояние между кластерами; если дело обстоит не так, то (3) последующие случаи заменят начальные центры кластера, если их самое маленькое расстояние от центра кластера большее расстояние того центра кластера от любого другого центра кластера. Эффект этой процедуры выбора должен развернуть начальные расстояния между кластерами. Обратите внимание, что эта процедура может выдавать кластеры с единственными (отдельными) наблюдениями, если есть ясный outliers в данных.
Переключатель Choose the first N (Number of clusters) observations. Если Вы выбираете этот переключатель, первые номера кластеров наблюдений будут начальными центрами кластера. Таким образом, эта опция обеспечивает Вас полным контролем над выбором начальной конфигурации. Это часто полезно, если Вы приносите априорные ожидания относительно характера (природы) кластеров к анализу. В этом случае, переместите случаи, которые Вы хотите выбрать как начальные центры кластера, к началу файла.
Переключатели Casewise deletion of missing data или Mean substitution в разделе MD deletion, первый следует использовать, если в анализ следует включать только случаи, которые имеют для всех переменных все данные, второй следует использовать, когда отсутствующие данные будут заменены средствами для соответствующих переменных (для этого анализа только, но не для файла данных). По умолчанию стоит переключатель Casewise deletion of missing data.
Оставить установленные по умолчанию переключатели и далее, в диалоговом окне Cluster Analysis: K-means clustering: следует нажать кнопку OK.
В появившемся диалоговом окне K-Means clustering Results: нажать кнопку Summary: Clusters means & Euclidean distances (рис. VII.19). В результате расчета получим матрицу дистанционных коэффициентов между кластерами рассчитанных по евклидовым метрикам (см. рис. VII.20). Здесь же рассчитываются средние по всем измерениям для каждого кластера.

Рис. VII.19. Анализ в K-Means clustering Results:
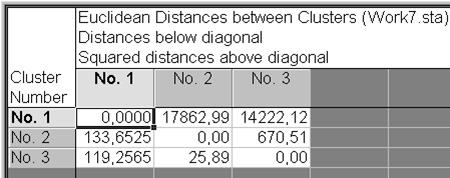
Рис. VII.20. Матрица евклидовых метрик между кластерами
Вернуться в диалоговое окно K-Means clustering Results: и нажать кнопку Analysis of variance. Анализ вариант следует использовать, если следует сравнивать изменчивость в пределах группы (within) (малая, если классификация хорошая) с изменчивостью между группами (between) (большая, если классификация хорошая), то есть выполнить дисперсионный анализ между группами для каждого измерения (рис. VII.21). Можно просмотреть результаты дисперсионного анализа, сравнивая для каждого измерения результаты между группами.
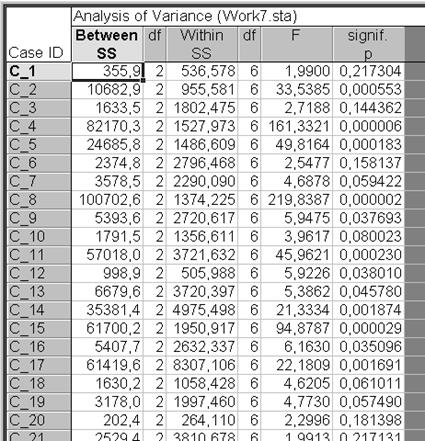
Рис. VII.21. Результат дисперсионного анализа Analysis of variance
Вернуться в диалоговое окно K-Means clustering Results: и нажать кнопку Graph of means. Результатом будет график средних по кластерам (рис. VII.22).

Рис. VII.22. График средних по кластерам
Вернуться в диалоговое окно K-Means clustering Results: и нажать кнопку Descriptive statistics for each cluster на вкладке Advanced. Результатом будет вывод крупноформатных таблиц описательной статистики для каждого измерения по кластерам (рис. VII.23).

Рис. VII.23. Дескриптивная статистика для третьего кластера
Вернуться в диалоговое окно K-Means clustering Results: и нажать кнопку Members of each cluster & distances. Результатом будет расчет евклидовых расстояний от центров кластеров для каждого элемента входящего в кластер (рис. VII.24). Это позволяет идентифицировать потенциальных «плохих» членов кластера.

Рис. VII.24. Евклидовы расстояния для каждого кластера
Вернуться в диалоговое окно K-Means clustering Results: и нажать кнопку Save classifications and distances. Результатом будет краткая электронная таблица содержащая: порядковые номера элементов (1 столбец), номер кластера, в который входит элемент (2 столбец) и евклидовы метрики для каждого элемента от соответствующего центра кластера (3 столбец) – рис. VII.25.
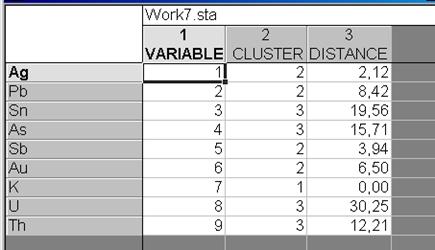
Рис. VII.25. Результат выполнения Save classifications and distances
7. Провести факторный анализ для выделения ассоциаций химических элементов. Для этого в меню с основными процедурами Statistics выбрать Multivariate Exploratory Techniques, а в появившемся его меню – Factor Analysis.
В появившемся диалоговом окне Factor Analysis: (см. рис. VII.26) на вкладке Quick нажать кнопку Variables и появившемся диалоговом окне Select the variables for the factor analysis нажать кнопку Select All (рис. VII.27). Вернуться в диалоговое окно Factor Analysis: и нажать кнопку OK (рис. VII.28).
Рис. VII.26. Диалоговое окно Factor Analysis:

Рис. VII.27. Выбор переменных для факторного анализа
Рис. VII.28. Диалоговое окно Factor Analysis: с выбранными переменными
Появится окно Define Method of Factor Extraction:, где выбираем на вкладке Descriptives (рис. VII.29) кнопку Review correlations, means, standard deviations. В диалоговом окне Review descriptive statistics (рис. VII.30) нажимаем кнопку Correlations. Результатом расчета будет корреляционная матрица (рис. VII.31). Она аналогична матрице, полученной в разделе корреляционного анализа и представленной на рис. VII.4.

Рис. VII.29. Диалоговое окно Define Method of Factor Extraction:
Рис. VII.30. Диалоговое окно Review descriptive statistics

Рис. VII.31. Корреляционная матрица
В диалоговом окне Review descriptive statistics нажимаем кнопку Cancel и возвращаемся в диалоговое окно Define Method of Factor Extraction:, где выбираем на вкладке Advanced в разделе Extraction method установленный по умолчанию метод Principal Components (метод главных компонент или факторов). В разделе Max no. of factors установить число 9 – максимальное число факторов в нашем случае, в разделе Mini. eigenvalue: 0 – минимальное значение для этой опции (рис. VII.32). Нажать кнопку OK. Открывается диалоговое окно Factor Analysis Results:, в котором выбирается вкладка Quick, где нажимается кнопка Eigenvalues (собственные значения) (рис. VII.33). Результатом расчета будет таблица Eigenvalues (частей от общего числа факторов, в данном случае – части от девяти), которая содержит следующие столбцы: собственные значения (Eigenvalues), проценты от полной величины (% Total variance), кумулятивных собственных значений (Cumulative Eigenvalues), и кумулятивного процента (Cumulative %) (рис. VII.34). Первые три фактора дают наибольший вклад в процентном отношении. Основываясь на таблице Eigenvalues, можно предложить рассматривать только эти три фактора.
Рис. VII.32. Выбор параметров в диалоговом окне Define Method of Factor Extraction:
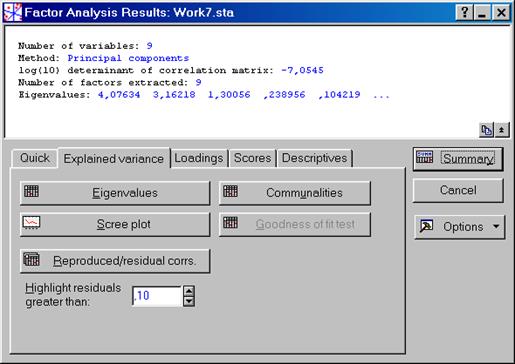
Рис. VII.33. Расчет Explained variance в диалоговом окне Factor Analysis Results:
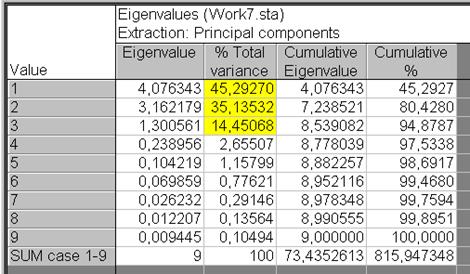
Рис. VII.34. Расчетная таблица Eigenvalues
В диалоговом окне Factor Analysis Results: выбрать вкладку Explained variance, где нажать кнопку Scree plot. Результатом будет график, основанный на тесте Каттелла (рис. VII.35), иллюстрирующий первый столбец таблицы Eigenvalues. Основанный на методе Монте-Карло, Cattell's scree test предлагает, что в точке, где непрерывное падение Eigenvalues выравнивается, предлагается сокращение остальных дополнительных факторов, так как только случайный «шум» добавляется дополнительными факторами. В нашем примере, эта точка может быть для фактора 3 или фактора 4. Поэтому нужно попробовать оба решения и рассмотреть тот, который выдаст наиболее поддающееся толкованию решение.
Теперь исследуем факторные нагрузки. Сначала следует рассмотреть невращаемые факторные нагрузки для всех 9 факторов. В диалоговом окне Factor Analysis Results: выбрать вкладку Loadings и в разделе Factor rotation: выбрать установленное по умолчанию – Unrotated. Обратите внимание, что считается, что факторы со значением нагрузки более 0,70 – факторы с высокой нагрузкой. Затем нажать на кнопку Summary (рис. VII.36). Результатом расчета будет таблица факторных нагрузок отсортированных так, чтобы последующие факторы составляли все меньшее и меньшее количество разницы (рис. VII.37). Не удивительно видеть, что первый фактор показывает большинство самых высоких нагрузок.
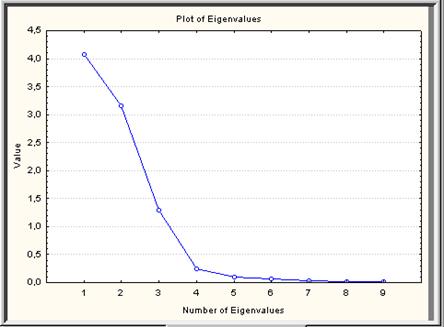
Рис. VII.35. График Scree plot
Рис. VII.36. Выбор Unrotated в диалоговом окне Factor Analysis Results: на вкладке Loadings в разделе Factor rotation:
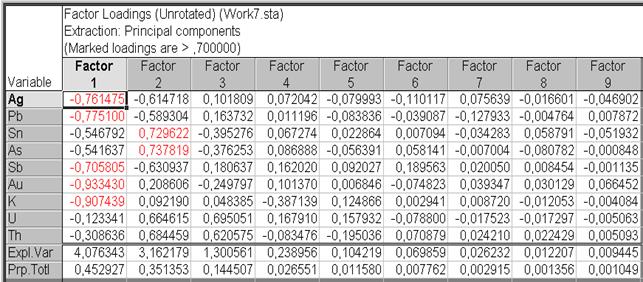
Рис. VII.37. Таблица факторных нагрузок по методу Unrotated для 10 факторов
Фактическая ориентация факторов в пространстве факториала произвольна и все вращения факторов в пространстве воспроизведут корреляции одинаково хорошо. Поэтому предложено вращать факторы таким образом, чтобы выдать такую структуру фактора, что ее проще интерпретировать. Такая простая структура и была определена Thurstone (1947), чтобы в основном описать состояние, когда факторы отмечены высокими нагрузками для некоторых переменных, низкими нагрузками для других, и когда есть немного высоких перекрестных нагрузок, то есть немного переменных с существенными нагрузками на больше, чем один фактор. Популярный стандартный вычислительный метода вращения, чтобы получить простую структуру – VARIMAX вращение (Kaiser, 1958); Другие, которые были предложены - QUARTIMAX, BIQUARTIMAX, и EQUAMAX (см. Harman, 1967) – все они осуществлены в STATISTICA.
Сначала рассмотрим число факторов, которое хотим вращать. Было предварительно решено, что три фактора являются наиболее влиятельными, но по результатам рассмотрения графика на рис. VII.35 было решено рассматривать четыре фактора. Нажать кнопку Cancel, чтобы возвратиться в окно Define Method of Factor Extraction:, где выбрать вкладку Quick. Установить в разделе Max no. of factors число 4 – число факторов в рассматриваемом случае, в разделе Mini. eigenvalue: 0 – минимальное значение для этой опции (рис. VII.38).

Рис. VII.38. Установка нового числа факторов в Max no. of factors
Нажать кнопку OK. Открывается диалоговое окно Factor Analysis Results:, в котором выбрать вкладку Loadings, и в списке Factor rotation: выбрать Varimax raw (рис. VII.39). Затем нажать на кнопку Summary. Результатом расчета будет таблица Factor Loadings (факторных нагрузок) – см. рис. VII.40. Получится вращаемое решение с четырьмя факторами. Четвертый фактор не дает больших нагрузок. Повторить решение для трех факторов. Результатом расчета будет таблица Factor Loadings (факторных нагрузок) – см. рис. VII.41. Первый фактор показывает большинство самых высоких нагрузок. Для золота (Au) большую нагрузку показывает второй фактор – около 0,82 и достаточно большую – первый фактор – около 0,55. Фактор 1 связан с Ag, Pb и Sb, фактор 2 – с Sn, As и Au, фактор 3 – с U и Th. С K, кажется, связан и фактор 1 и фактор 2: фактор 1 – нагрузка 0,66, фактор 2 – 0,57.
Рис. VII.39. Выбор Varimax raw в диалоговом окне Factor Analysis Results: на вкладке Loadings в разделе Factor rotation:

Рис. VII.40. Таблица факторных нагрузок по методу Varimax для 4 факторов

Рис. VII.41. Таблица факторных нагрузок по методу Varimax для 3 факторов
Щелкнуть в диалоговом окне Factor Analysis Results: на вкладке Loadings кнопкой Plot of loadings, 2D. Откроется диалоговое окно Select two factors for the plot, в котором выберем Factor 1 и Factor 2 (рис. VII.42). Нажать OK. Результатом будет плоский график нагрузок (рис. VII.43). Аналогично построить график нагрузок для Factor 1 и Factor 3 (рис. VII.44). В диалоговом окне Factor Analysis Results: на вкладке Loadings щелкнем кнопкой Plot of loadings, 3D. Результатом будет трехмерный график нагрузок (рис. VII.45).

Рис. VII.42. Диалоговое окно Select two factors for the plot
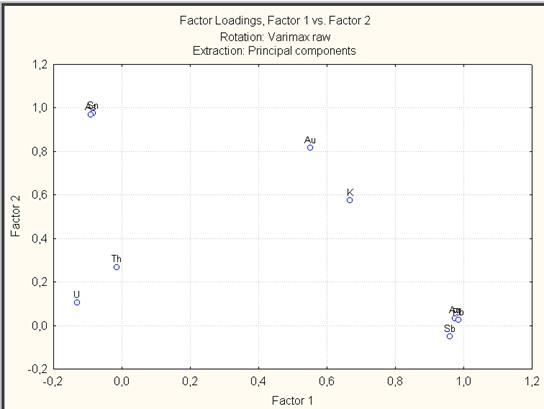
Рис. VII.43. График нагрузок Plot of loadings, 2D для факторов 1 и 2
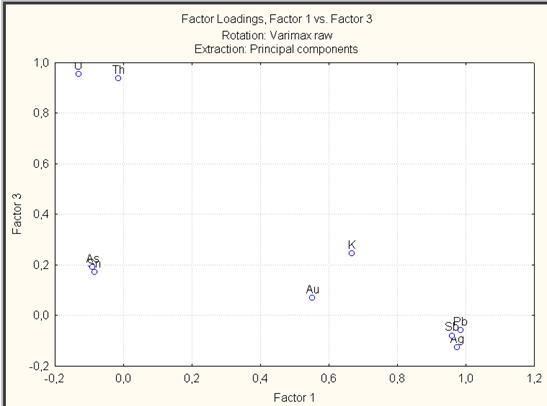
Рис. VII.44. График нагрузок Plot of loadings, 2D для факторов 1 и 3

Рис. VII.45. График нагрузок Plot of loadings, 3D для факторов 1, 2 и 3
Графики (рис. VII.43 – VII.45) просто показывают нагрузки для каждой переменной и хорошо иллюстрируют корреляционную матрицу, например, по рис. VII.43 видно, что ассоциированы мышьяк (As) и олово (Sn); серебро (Ag), сурьма (Sb) и свинец (Pb); уран (U) и торий (Th). Фактор 2 – фактор с высокими нагрузками на Au – «рудный» и фактор 3 связан с околорудным метасоматозом. Обратите внимание на нагрузки факторов, для того, чтобы определить, в какой мере данная закономерность характеризует изучаемый объект.
Щелкнуть в диалоговом окне Factor Analysis Results: на вкладке Explained variance кнопкой Reproduced/residual corrs. (рис. VII.46), чтобы получить две матрицы – корреляции и остаточной корреляции (рис. VII.47).

Рис. VII.46. Диалоговое окно Factor Analysis Results: вкладке Explained
Таблица остаточных корреляций может интерпретироваться как «количество» корреляции, которое не может быть объяснено решением с тремя факторами. Диагональные элементы в матрице содержат стандартное отклонение, которое является равным квадратному корню из единицы минус соответствующие общности для двух факторов (общности переменной – разница, которую можно объяснять соответствующим числом факторов). Если рассмотреть тщательно эту матрицу, можно видеть, что нет фактически никаких остаточных корреляций, которые являются большими, чем 0,1, или меньше чем –0,1. Добавить к этому факт, что первые три фактора объясняли почти 95 % полной разницы (см. совокупный % Eigenvalues показанный в таблице Eigenvalues на рис. VII.34). Очень низкие общности для одной или двух переменных (из всех в анализе) могут указывать, что эти переменные плохо объясняются соответствующей моделью фактора.
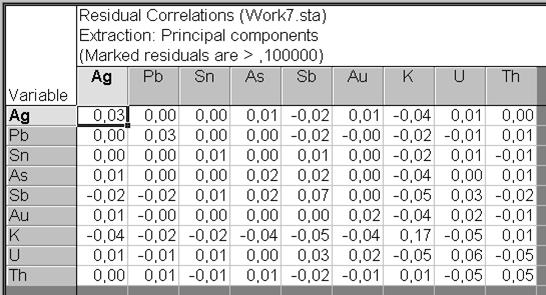
Рис. VII.47. Таблица остаточных корреляций
Щелкнуть в диалоговом окне Factor Analysis Results: на вкладке Explained variance кнопкой Communalities (рис. VII.46), чтобы получить таблицу общностей для текущего решения, то есть текущего числа факторов (рис. VII.48).

Рис. VII.48. Таблица общностей
Щелкнуть в диалогом окне Factor Analysis Results: на вкладке Scores кнопкой Factor scores coefficients, чтобы получить таблицу со значениями каждого фактора элементов (рис. VII.49). Эти коэффициенты представляют веса, которые используются когда вычисляется зависимость фактора от переменных.
Щелкнуть в диалогом окне Factor Analysis Results: на вкладке Scores кнопкой Factor scores, чтобы получить таблицу со значениями каждого фактора в точках наблюдения (рис. VII.50). Обратите внимание, в каких точках наблюдения значения рудного фактора наибольшие: 4 – 6, 11, 17, 19, 21, 24. Фактор околорудного метасоматоза – 1, 4, 8, 13 – 15, 20, 21, 24, 26 – 28, 31, 33 – 34, 36. Общие: 4, 21, 24.

Рис. VII.49. Таблица Factor scores coefficients

Рис. VII.50. Таблица Factor scores
В таблице Factor scores выделить «рудный» фактор» – 2 и фактор околорудного метасоматоза – 3. Затем выбрать процедуру графического анализа в контекстном меню Graphs of Block Data\Line Plots: Entire Columns. На полученном графике указать места, где максимально проявлены факторы рудного метасоматоза (рис. VII.51).

Рис. VII.51. Результат выполнения процедуры в контекстном меню Graphs of Block Data\Line Plots: Entire Columns.
8. Сделать окончательные выводы о геохимических ассоциациях элементов и прогнозной значимости объекта.
Сравнить результаты корреляционного, кластерного и факторного анализов, их отличия, связанные с возможностями каждого анализа, и общие черты, позволяющие дать взвешенное заключение о закономерных связях между изучаемыми признаками.
ОБЛАСТЬ ПРИМЕНЕНИЯ МНОГОМЕРНЫХ СТАТИСТИЧЕСКИХ МОДЕЛЕЙ В ГЕОЛОГИИ
Возможности применения многомерных статистических моделей для изучения взаимозависимостей комплексов самых различных геологических признаков практически не ограничены для любой отрасли геологии. В палеонтологии они используются для статистического описания морфологических признаков ископаемых форм организмов и сопоставления их групп с литолого-фациальными разрезами осадочных пород, с целью оценки достоверности их стратиграфического положения (или установления групп руководящих ископаемых). Корреляционные методы парагенетического анализа химических элементов и минералов находят широкое применение в геохимии и минералогии. Различные методы многомерного описания самых различных физических свойств, химического и минерального состава осадочных и магматических пород используются в литологии и петрографии для разделения их по фациальным или формационным признакам или для оценок их перспектив на выявление самых различных полезных ископаемых. С каждым годом все шире используются методы «распознавания образов» рудоносных территорий или месторождении полезных ископаемых, основанные на статистических описаниях сочетаний благоприятных элементов геологического строения, влияющих на концентрации полезных ископаемых. В настоящее время алгоритмы «распознавания образов», использующие самые различные статистические, логические и эвристические многомерные модели, реализуются в человеко-машинных информационно-прогнозирующих системах, на шедших широкое применение в геологоразведочной отрасли.
Многомерные статистические описания связей геологических переменных с последующими оценками степени их взаимозависимостей используются в геологической практике с целью идентификации (отождествления), дискриминации (разделения), классификации (группирования) изучаемых объектов или в поисках наиболее информативных комбинаций признаков для решения прогнозных задач.
Задачи идентификации геологических объектов, например, оценки коллекторских свойств или газоносности пород по совокупности скважинно-геофизических характеристик, обычно выполняются с помощью моделей множественной регрессии.
В целях дискриминации геологических объектов на два заранее заданных класса, например, разделение кимберлитовых пород на алмазоносный и неалмазоносный типы, по данным их силикатных анализов может быть использована модель линейной дискриминантной функции.
Классификация геологических объектов, например, иерархическое группирование парагенетических ассоциаций элементов метасоматически измененных пород или руд по данным их полных химических анализов производится с помощью кластер-анализа, других методов многомерного корреляционного анализа или метода факторного анализа.
Конечной целью большинства многомерных статистических методов является предсказание (прогнозирование) тех или иных свойств изучаемых геологических объектов.
Прогнозирование свойств геологических объектов, чаще всего выявление перспектив их рудоносности или оценка вероятных масштабов оруденения проводится с помощью алгоритмов «распознавания образов».
В зависимости от характера исходных данных и целей геологических исследований для составления этих алгоритмов используются самые различные многомерные модели. При этом, как правило, возникает проблема поиска наиболее информативных сочетаний признаков и сокращения размерности их пространства, что достигается с помощью метода главных компонент, R -метода факторного анализа или других логических и эвристических методов.
Возможности использования многомерных статистических моделей для целей решения геологических задач изучены в настоящее время далеко не полностью и несомненно имеют большое будущее.
ЛАБОРАТОРНАЯ РАБОТА № VIII. МНОГОМЕРНЫЕ СТАТИСТИЧЕСКИЕ МОДЕЛИ. ЗАДАЧИ РАСПОЗНАВАНИЯ ОБРАЗОВ В ГЕОЛОГИИ
Многие прогнозные и интерпретационные задачи решаются в практической геологии путем сопоставления комплекса признаков изучаемого объекта с комплексом тех же признаков эталонного объекта. Совокупность подобных методов, основанных на принципе аналогии, получила название методов распознавания образов.
Модели распознавания образов геологических объектов весьма разнообразны. При решении конкретных геологических задач их выбор зависит от природы геологических объектов, числа, полноты описания эталонных объектов, типов и информативности их признаков. В зависимости от типов исходных признаков выделяют две группы моделей: дискретные и непрерывные.
Дискретные модели применяются в тех случаях, когда измеряемые признаки рассматриваются как независимые или частично зависимые детерминированные величины.
Непрерывные модели используются для распознавания образов таких объектов, измеряемые признаки которых могут рассматриваться как случайные величины и поддаются статистическому описанию многомерными функциями плотностей вероятности.
В качестве критериев оптимальности распознавания используются решающие правила, определяющие пороговые значения решающих функций. Они могут определяться статистическими, логическими или эвристическими * методами.
При использовании любых алгоритмов распознавания следует стремиться к построениям решающих функций как можно более простых видов, поскольку они легче поддаются реализации и обеспечивают более устойчивые решения, особенно при малых выборках обучения.
Линейная дискриминантная функция для трех переменных имеет вид
 . (VIII.1)
. (VIII.1)
Коэффициенты a 1, a 2 и a 3 находятся из системы уравнений
 (VIII.2)
(VIII.2)
Величины d 1, d 2 и d 3 представляют собой разности оценок средних значений признаков по выборкам A и B.
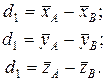 (VIII.3)
(VIII.3)
Если обозначить номер строки как i, а столбца как j, то величины sij можно записать в форме матрицы:
 . (VIII.4)
. (VIII.4)
Значения sij соответствуют элементам ковариационной матрицы признаков X, Y, Z и вычисляются, как суммы квадратов отклонений или суммы смешанных произведений отклонений:

Приведенные выше выражения для удобства расчетов могут быть заменены на эквивалентные выражения для сумм квадратов вида
 , (VIII.5)
, (VIII.5)
и для сумм смешанных произведения вида
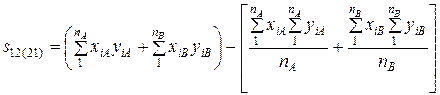 , (VIII.6)
, (VIII.6)
где nA и nB – объем выборки для объекта A и B.
После вычисления коэффициентов a 1, a 2 и a 3, необходимо вычислить значение функции D 0, относительно которого можно сделать вывод о принадлежности нового неизвестного объекта к тому или иному классу (свите)
 . (VIII.6)
. (VIII.6)
В Excel для вычисления ковариации используется процедура Ковариация. Процедура позволяет получить ковариационную матрицу, содержащую коэффициенты ковариации между различными параметрами.
Для реализации процедуры необходимо:
· выполнить команду Сервис/Анализ данных;
· в появившемся списке Инструменты анализа выбрать строку Ковариация и нажать кнопку OK;
· в появившемся диалоговом окне указать Входной интервал, то есть ввести ссылку на ячейки, содержащие анализируемые данные. Для этого следует навести указатель мыши на левую верхнюю ячейку данных, нажать левую кнопку мыши и, не отпуская ее, протянуть указатель мыши к правой нижней ячейке, содержащей анализируемые данные, затем отпустить левую кнопку мыши. Входной интервал должен содержать не менее двух столбцов.
· в разделе Группировка переключатель установить в соответствии с введенными данными;
· указать выходной диапазон, то есть ввести ссылку на ячейки, в которые будут выведены результаты анализа. Для этого следует поставить флажок в левое поле Выходной интервал (навести указатель мыши и щелкнуть левой кнопкой), далее навести указатель мыши на правое поле ввода Выходной интервал и щелкнуть левой кнопкой мыши, затем указатель мыши навести на левую верхнюю ячейку выходного диапазона и щелкнуть левой кнопкой мыши. Размер выходного диапазона будет определен автоматически, и на экран будет выведено сообщение в случае возможного наложения выходного диапазона на исходные данные.